
用tensorflow.js辦識驗證碼字母
接續上一篇用js生成一套驗證碼字母,這篇使用tensorflow.js來訓練一個模型去辦識這款驗證碼。
如果想重溫驗證碼製作方法,按此傳送門
這邊我做了個 demo 放在Github,讓大家可以親自體驗使用tfjs做訓練,原碼可以在 這裡 找到。下面我來説明一下是如何使用的。
首先䦕個新分頁到我的Demo page: https://doggor.github.io/tfjs-text-classification-demo/ ,應該會看到一行操作欄:
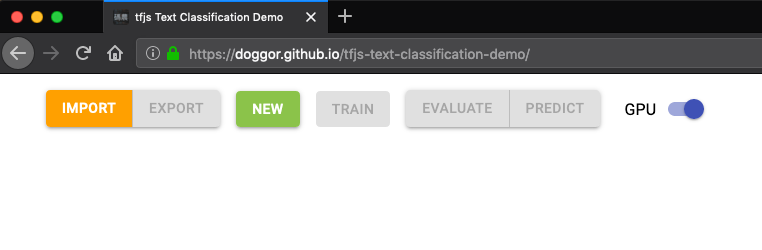
簡單說明一下每個按鈕作用:
Import:𣾀入模型,讀取先前滙出的模型檔案並存放至indexedDB;Export:𣾀出模型,將當前模型滙出成兩個檔案(一個描述模型結構,另一個是模型參數)並下載;New:創建新模型,將同時儲存至indexedDB;Train:訓練當前選擇模型,然後將訓練後的參數儲存至indexedDB;Evaluate:評估當前模型效能;Predict:使用當前模型預測一組隨機生成的驗證碼;GPU:如果瀏覽器支援webGL則預設啟用,開啟畤會使用GPU訓練和執行模型,關閉時則使用CPU。
剛開始我們沒有任何模型可用。點擊New來建立一個新模型:
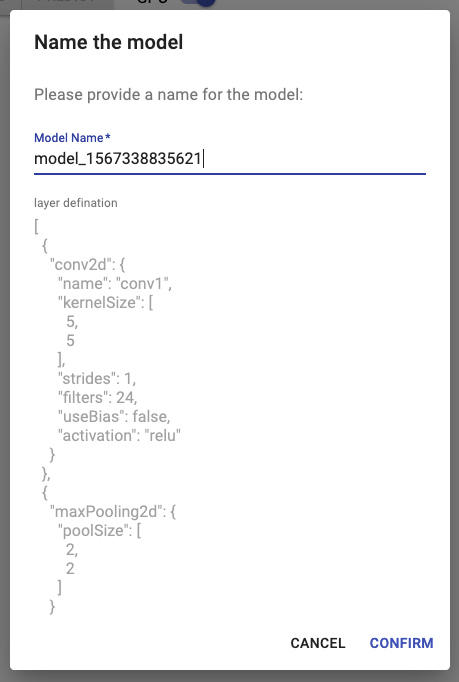
預設會給予一個隨機名字,你可以直接使用它,或者改一個容易記憶、有意義的名字。要注意一點,如果已經存在同名的模型,它將會被覆蓋。
這裡你可以定義自己的模型,格式為JSON,模型會轉化成為tf.sequential,即該JSON object必需是一個Array。預設如下:
[
{ "conv2d": { "name": "conv1", "kernelSize": [5, 5], "strides": 1, "filters": 24, "useBias": true, "activation": "relu" } },
{ "maxPooling2d": { "poolSize": [2, 2] } },
{ "conv2d": { "name": "conv2", "kernelSize": [3, 3], "strides": 1, "filters": 24, "useBias": true, "activation": "relu" } },
{ "maxPooling2d": { "poolSize": [2, 2] } },
{ "flatten": {} },
{ "dense": { "name": "dense1", "useBias": true, "activation": "relu" } }
]
程式會為第一層自動補上input shape和batch size,也為最後一層補上units確保輸出維度是[, 62]。Array中每個Object表示一層Layer,以{layer_type: properties}型式定義。layer_type可用名字能在tf.layers.*中找到,properties為該layer_type可用的設定,跟直接使用js編寫很相似。
起初你可以基於上面預設值作少許修改,例如這樣:
[
{ "conv2d": { "name": "conv1", "kernelSize": [5, 5], "strides": 1, "filters": 24, "useBias": true, "activation": "relu" } },
{ "maxPooling2d": { "poolSize": [2, 2] } },
{ "conv2d": { "name": "conv2", "kernelSize": [3, 3], "strides": 1, "filters": 24, "useBias": true, "activation": "relu" } },
{ "maxPooling2d": { "poolSize": [2, 2] } },
{ "flatten": { "name": "flatten1" } },
{ "dense": { "name": "dense1", "units": 128, "useBias": true, "activation": "relu" } },
{ "dense": { "name": "dense2", "useBias": true, "activation": "softmax" } }
]
如果你是笫一次使用,建議先直接使用預設值。
確定後,會看到這個新模型在操作欄下方:
點選這個模型,頁面的右方會彈出有關模型的資訊,這是使用 tfjs-vis 做的:
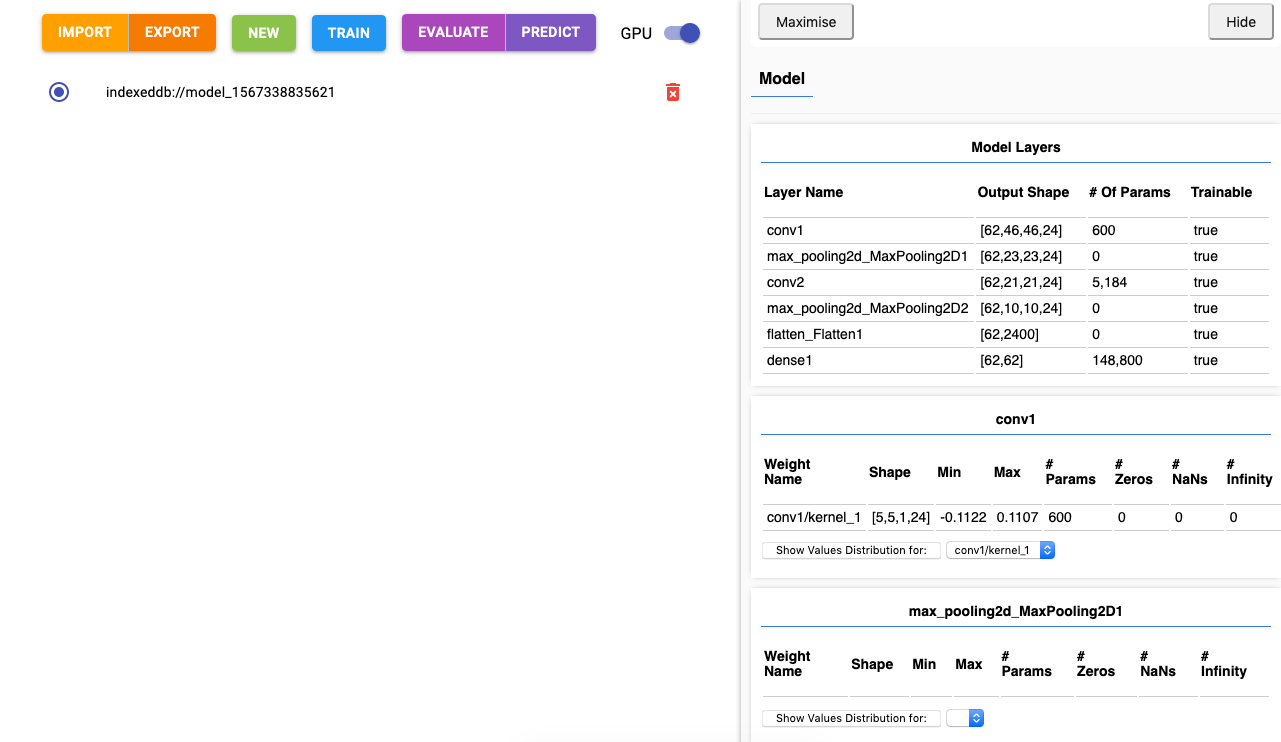
上面顯示了模型構造:先經過兩層 convolution + pooling,然後flatten平攤成一維陣列,最後經過一個全連接層(dense)𨌺出。可以清楚看出每層的資料輸出形狀(Output Shape),與及需要訓練的參數個數(# of Params)。Model Layers下方顯示各層參數的數值分佈,你可以觀察一下模型訓練前和訓練後的參數變化。
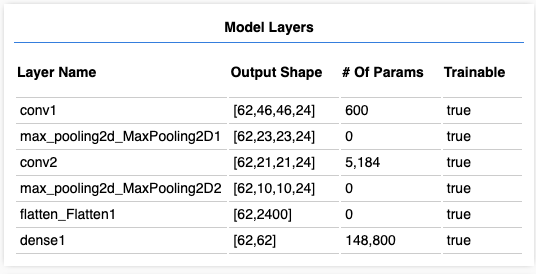
接著我們來進行訓練。每一次訓練(1 epoch)都會採用一組新生成的數據,每組數據為09 + az + A~Z共62個字母不重複的驗證碼圖片。
對於一個未經訓練的模型,它對這62個字母形狀並無任何概念,僅僅進行一次訓練不能把當中的字母辨別出來。想想如果是一種你不認識的文字:韓文、日文、泰文、古埃及文…然後每個字做成驗證碼,只給你看一次,認得到算你神。
所以接下來訓練它100次來看看成果。點選Train按鈕,epochs設定為100,然後確認:
訓練採用的Optimizer是Adam,一種效率比較好的參數優化器,Loss計算則是categoricalCrossentropy,適用於多分類埸境,像這次案例要把驗證碼圖片分類到62種字母之中。
訓綀時會出現TrainingTab,當中有兩個線圖,第一個是模型的loss(損失,即當前模型斦預測的結果與正確答案之間相差多少),第二個是Accuracy(精準度,預測出正確答案的比率)。完成訓練後兩個線圖應該會有以下類似的形狀:
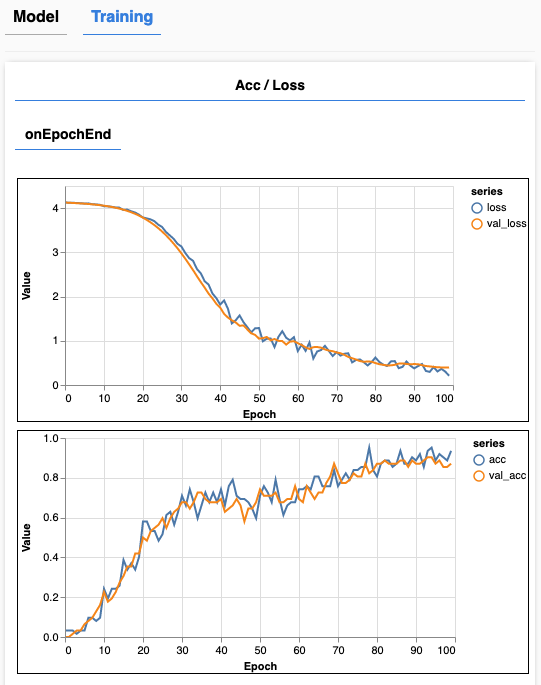
在每一次訓練後,為了確認模型在實際應用時的成效,我們會同時採用另一組新的數據(validation set)來計算它的loss和accuracy,模擬未曾接觸過的真實數據,顯示為黃色線;藍色線則是拿原本用來做訓練的數據來計算的。
在loss圖表上,如果兩條線居高不下,表示模型未能有效理解數據(underfit),它需要比現在更複雜的結構;如果黃色線在某個位置不再跟隨藍色線往下走,表示模型對訓練用的數據過份熟悉(overfit),卻對未曾接觸過的數據很陌生,實際應用時容易判斷出錯,需要簡化一下結構。
這𥚃由於每次訓練所使用的數據都是重新生成的,不是重用同一組數豦,所以不會出現overfit(每次接觸的數據都很陌生喔)。而從圖中可見loss持續往下行,最終位置不算高,沒明顯出現underfit。
完成訓練後,我們給它做個測驗,看一看它成積如何。在操作欄點選Evaluate,等待Accuracy和Confusion Matrix圖表出現:
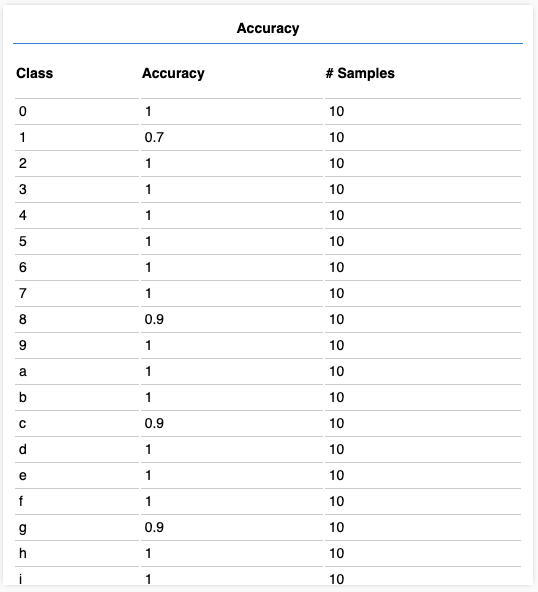
這個測驗會生成10組數據給模型做預測。Accuracy圖表顯示每個字母的預測凖確率,Confusion Matrix顯示每個字母被預測成各種字母的次數。遺憾的是,把這62個分類一並顯示在如此狹小的空間,可以得知大概形狀但無法看清楚上面的數字,有點杯具……
tfjs-vis方便但不好用,UI體驗有點不足
最後讓我們感受一下實際成果。點選Predict等待結果(相比Evaluate這次只預測一組數據,結果應該會較快顯示出來):
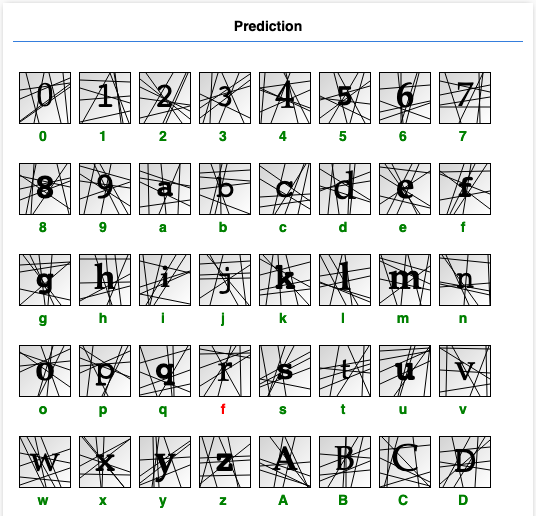
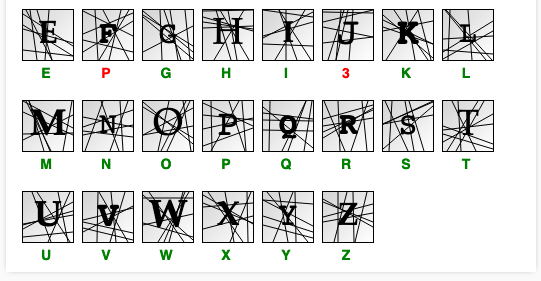
每個驗證碼下方是其預測值,綠色表示預測正確,紅色則錯誤。
從以上結果看出,這個模型對某些肉眼可輕易分別的驗證碼作出了誤判,代表它可能對數據理解不夠深入。你可以嘗試增加訓練次數、增加模型層數、或某些層的節點數來提升它的理解力。
之後可以試一試Export你的模型,或者Import你朋友的模型大家比較一下。
順帶一提,使用GPU做訓練的話epoch不能設定太高,因爲Tensorflow.js會不斷請求新的WebGL Context資源而不會釋放(bug?),最終GPU資源耗盡導致程序崩潰。對於這個問題,只要刷新頁面便會立即釋放其擁有的GPU資源。